 Justin Jenkins3 min read
Justin Jenkins3 min readMongoDB Query Plans: The Basics
Optimizing the performance of MongoDB relies heavily on effective querying. However, determining areas for optimization in a query can be challenging.
This is where the concept of a query plan comes into play … an amazing tool for developers and database administrators to pinpoint and address performance bottlenecks.
What is a Query Plan?
In MongoDB, a query plan is a detailed explanation of how the database engine executes a specific query. To access this information, you can append the explain() method to your find() query.
db.cookbook.find(
{ "type": "Dinner" }
).explain()
This returns a comprehensive set of data, which will look something like the following:
{
explainVersion: '1',
queryPlanner: {
namespace: 'cookbook.cookbook',
indexFilterSet: false,
parsedQuery: { type: { '$eq': 'Dinner' } },
queryHash: '3D98D089',
planCacheKey: '3D98D089',
maxIndexedOrSolutionsReached: false,
maxIndexedAndSolutionsReached: false,
maxScansToExplodeReached: false,
winningPlan: {
stage: 'COLLSCAN',
filter: { type: { '$eq': 'Dinner' } },
direction: 'forward'
},
rejectedPlans: []
},
command: { find: 'cookbook', filter: { type: 'Dinner' }, '$db': 'cookbook' },
serverInfo: {
host: 'myserver',
port: 27017,
version: '6.0.6',
gitVersion: '26b4851a412cc8b9b4a18cdb6cd0f9f642e06aa7'
},
serverParameters: {
internalQueryFacetBufferSizeBytes: 104857600,
internalQueryFacetMaxOutputDocSizeBytes: 104857600,
internalLookupStageIntermediateDocumentMaxSizeBytes: 104857600,
internalDocumentSourceGroupMaxMemoryBytes: 104857600,
internalQueryMaxBlockingSortMemoryUsageBytes: 104857600,
internalQueryProhibitBlockingMergeOnMongoS: 0,
internalQueryMaxAddToSetBytes: 104857600,
internalDocumentSourceSetWindowFieldsMaxMemoryBytes: 104857600
},
ok: 1
}
For our purposes, we are interested in the “winning plan,” which provides insights into the most efficient way the database executed the query. We can get only this part of the result my using dot notation on our result:
db.cookbook.find(
{ "type": "Dinner" }
).explain().queryPlanner.winningPlan
This will return a result which looks something like this:
{
stage: 'COLLSCAN',
filter: { type: { '$eq': 'Dinner' } },
direction: 'forward'
}
Or, you can use MongoDB Compass (the official GUI for MongoDB) and see a similar result:
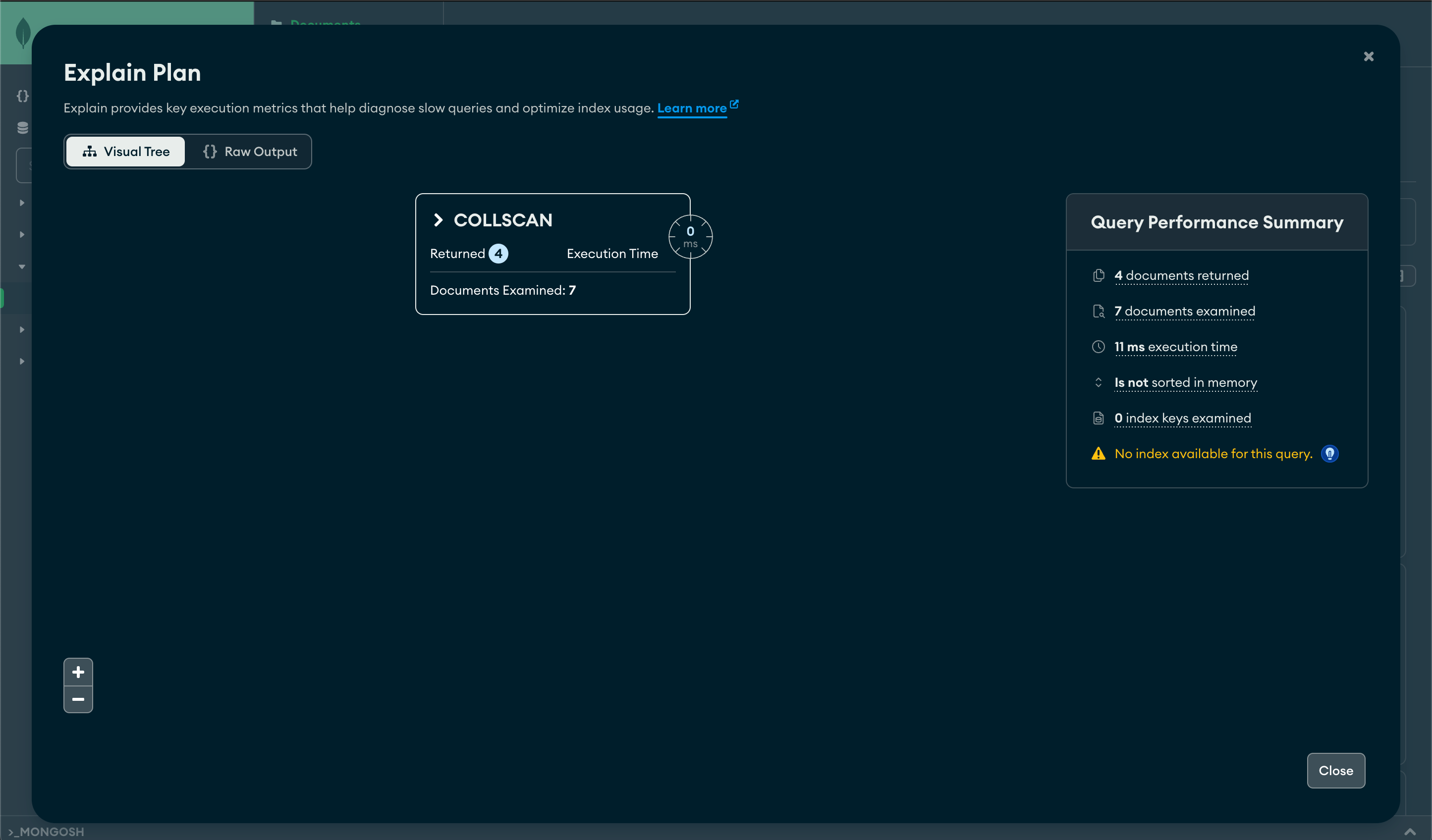
Depending on your version of Compass you might see a little warning and insight on the Query Performance Summary, and its suggestion is exactly what we need to do to solve this problem.
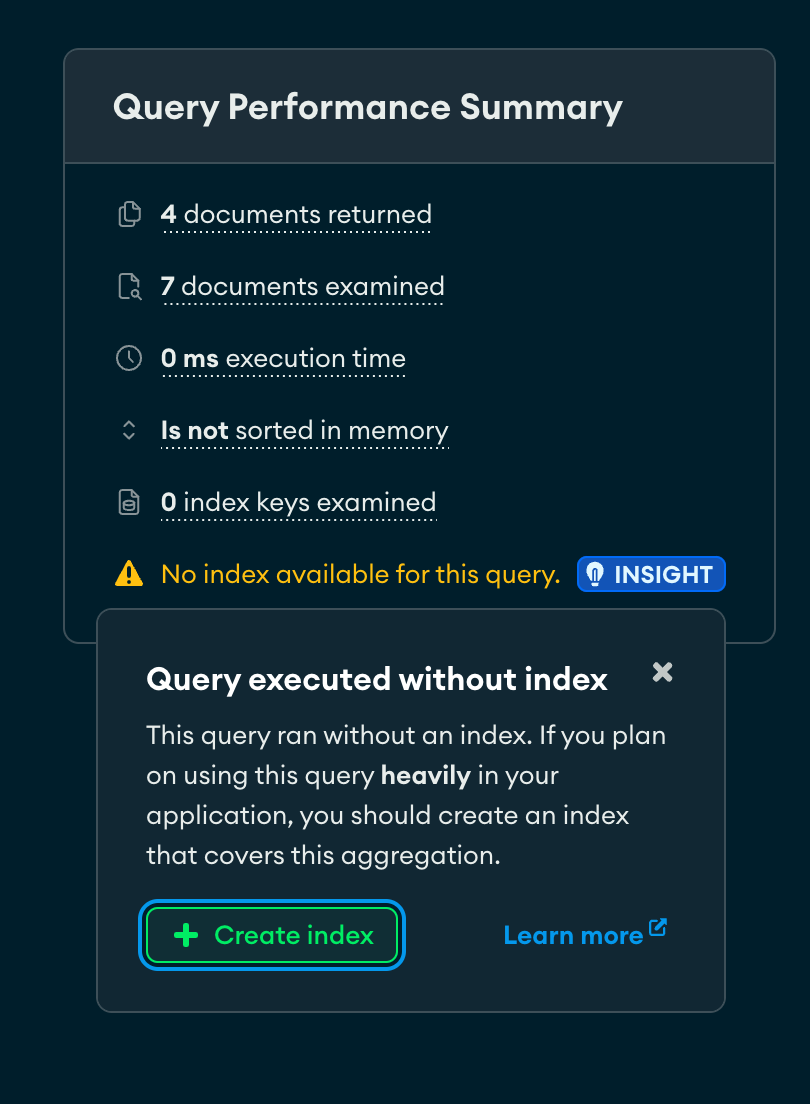
However let’s dig into what is going on here, first.
Understanding COLLSCAN
We can see in this example where MongoDB performs a COLLSCAN, or collection scan.
{
stage: 'COLLSCAN',
filter: { type: { '$eq': 'Dinner' } },
direction: 'forward'
}
This implies that the database had to examine every document in the collection to identify the desired match since no index was available for the specified query.
Moreover, the Documents Examined metric is 7, indicating that all documents in the collection were evaluated. This approach is not very efficient, especially when dealing with large datasets.
Optimizing with Indexes
The efficiency of query execution can be significantly improved by utilizing indexes. To do so we will add an index to the type field. If you don’t recall how to do that, the command is fairly simple:
db.cookbook.createIndex(
{ "type": 1 }, { "name": "ix_type" }
)
Now, if we run our query and explain() again:
db.cookbook.find(
{ "type": "Dinner" }
).explain().queryPlanner.winningPlan
This will return an new query plan:
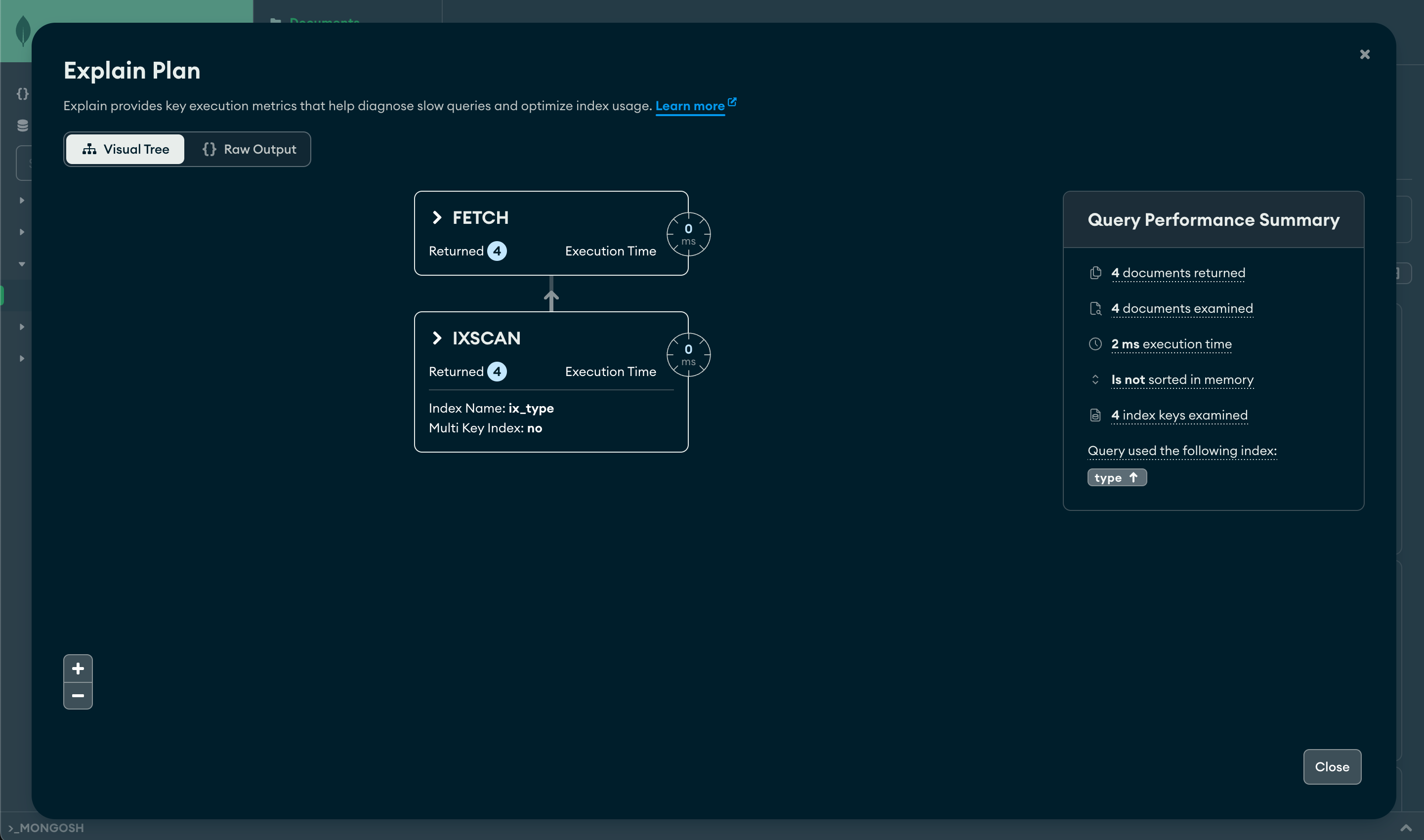
{
stage: 'FETCH',
inputStage: {
stage: 'IXSCAN',
keyPattern: { type: 1 },
indexName: 'ix_type',
isMultiKey: false,
multiKeyPaths: { type: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { type: [ '["Dinner", "Dinner"]' ] }
}
}
Notice the transition from COLLSCAN to IXSCAN (index scan). MongoDB can now leverage the index on the type field, eliminating the need to scan the entire collection. This results in a substantial performance boost!
In MongoDB Compass you can visually see the change as well:
Key Takeaways
COLLSCANvs.IXSCAN: Understanding the difference between collection scans and index scans is vital for optimizing query performance.- Documents Examined: Aim to minimize the “Documents Examined” metric, as it directly correlates with the efficiency of your queries.
- Utilizing MongoDB Compass: Developers can also leverage MongoDB Compass to visualize and analyze query plans, making it easier to identify performance bottlenecks.
Conclusion
MongoDB query plans provide valuable insights into how the database engine executes your queries. By carefully analyzing these plans, you can make informed decisions to optimize your queries and enhance overall database performance. Utilizing indexes effectively is a powerful strategy to minimize the need for collection scans, resulting in faster and more efficient query execution.
Discussion 1
Got something to say?
or to join the conversation.