Regression vs Classification overview and explaining three common machine learning algorithms
Which should I use?

Imagine you're throwing a party, and you want to know how many people are going to show up. You could ask all your friends, "Hey, are you coming to my party?" and write down their answers, but that would take a long time.
Instead, you could use regression or classification to make predictions about how many people will show up.
Regression is like asking your friends, "How many people are you bringing to the party?" and then adding up all their answers to get an estimate of the total number of guests. This works well if you have a lot of information about each person's party habits and can make a good guess about how many people they'll bring.
Classification is like asking your friends, "Are you bringing more than three people to the party?" and then grouping their answers into "yes" or "no" categories. This works well if you don't have a lot of information about each person's party habits, but you can make some assumptions based on past experience.
So, in summary, regression is like adding up a bunch of numbers to get a total, while classification is like putting things into categories based on certain criteria. Both can be useful for predicting outcomes in different situations, like predicting how many people will show up to your party!
Which algorithm should I use?
In reality the answer to this question is almost always Linear or Logistic regression. But people want to read about machine learning so we will save that articule for another day.
Let's take a look at a few of the 'sexier' foundation machine learning algorithms we can use on our data by exploring the differences between three popular algorithms: support vector machine, naive Bayes, and random forest.
What even is a Support Vector Machine?
Who knew maths could be so fun? Support vector machines are the ultimate mathlete of supervised learning algorithms, perfect for classification and regression analysis. They work by finding a hyperplane in a high-dimensional space that maximizes the distance between data points from different classes. Talk about impressive! This hyperplane is known as the margin, and the data points closest to it are called support vectors.
SVMs are the superheroes of datasets with a large number of features. They're also great at handling non-linear data, thanks to their ability to transform data into higher-dimensional space using kernel functions.

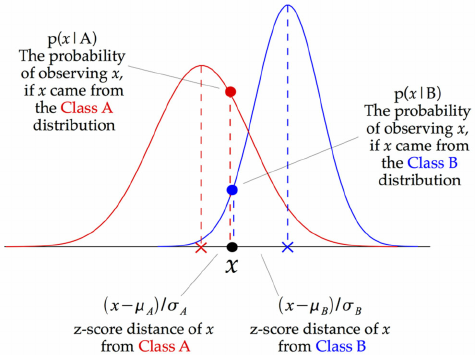
What in the heck is is a Naive Bayes algorithm?
If you're looking for a simple and efficient algorithm, then look no further than naive Bayes. This probabilistic algorithm is perfect for classification problems, using Bayes' theorem to calculate the probability of a given data point belonging to a particular class. It's called "naive" because it assumes that the features of a data point are independent of each other. Don't worry if you don't get it at first, we'll simplify it for you!
Naive Bayes is perfect for large datasets with high-dimensional feature spaces. However, because it assumes the features are independent, it may not always make accurate predictions. It's like asking a friend for their opinion, sometimes they get it right, but other times they miss the mark.
A random who?
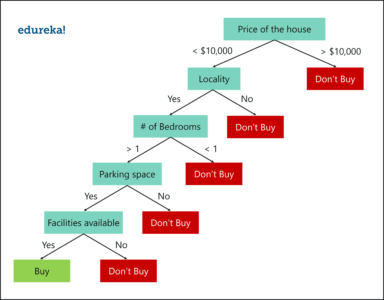
Are you ready for a party? Random forest is the ensemble learning algorithm that you've been waiting for! It uses multiple decision trees to make predictions, creating a set of decision trees that are trained on a random subset of data and features. The predictions of these individual trees are then combined to make a final prediction.
Random forest is the life of the party! It can handle both classification and regression problems and is perfect for dealing with noisy data and missing values. However, it can be a bit of a diva when it comes to computation power, and its output is not always easy to interpret. Think of it like a quirky artist, who sometimes produces masterpieces, but other times leaves you scratching your head.
So what did we learn?
A regression algorithm is great for predicting numbers in the future whereas classification is putting things into categories based on certain criteria.
A Support vector Machine is like Linear regression on steroids!
A naive Bayes is great, runs using probabilities, works when we have probabilistic outcomes.
Random forests work well for regression and classification and are ideal when we need something easy to understand!
I hope we've made the choice of machine learning algorithm a little less intimidating. So, let's go out there and make some predictions!
